Introduction
Supported Model Vendor:
- OpenAI
- Cohere
- Google Gemini
- xAI
- Doubao
A quick demo of private RAG is shown below and make sure you have the API KEY.
$ git clone https://github.com/YAKNetwork/YAK
$ cd YAK
$ DOUBAO_API_KEY=$DOUBAO_API_KEY cargo run --bin rag --features=derive
Successfully loaded and chunked PDF documents
Successfully generated embeddings
Successfully created vector store and index
Starting CLI chatbot...
Welcome to the chatbot! Type 'exit' to quit.
> hello!
========================== Response ============================
Hi! Is there a specific question you have related to the provided documents? If so, please let me know and I'll do my best to answer.
================================================================
> brief summary the docs
========================== Response ============================
The provided documents cover different topics:
- **Moore's Law for Everything (parts 1 and 9)**
- Discusses the need for a pivot towards the future, considering the radically different society that's approaching. It predicts an AI revolution that will be the fourth great technological revolution after the agricultural, industrial, and computational ones. This revolution could generate wealth for all if managed responsibly. It also mentions that technology will drive down the cost of goods, increasing societal wealth. The changes are unstoppable, and if embraced and planned for, they can lead to a fairer, happier, and more prosperous society.
- **Last Question (parts 6 and 13)**
- In part 6, characters discuss concerns about the future as the Galaxy is expanding and will be filled in five years at the current rate. They consider submitting a report to the Galactic Council and debate the implications of immortality and the Galactic AC's solutions. Part 13 simply contains the phrase "there was light --", which provides little context on its own but may be part of a larger narrative.
================================================================
> quit
========================== Response ============================
Okay. If you have any other questions later, feel free to come back. Have a great day!
================================================================
Installation
Private Embedding
Vector Embeddings
Vector embeddings are numerical represenatations of unstructured data, such as text, images or audios and even the videos in the form of vectors. These embeddings capture the semantic similarity of objects by mapping them to points in a vector space, where similar objects are represented by vectors that are close to each other.
Example
For example, in the case of text data, “cat” and “kitty” have similar meaning, even though the words “cat” and “kitty” are very different if compared letter by letter. For semantic search to work effectively, embedding representations of “cat” and “kitty” must sufficiently capture their semantic similarity. This is where vector representations are used, and why their derivation is so important.
In practice, vector embeddings are arrays of real numbers, of a fixed length (typically from hundreds to thousands of elements), generated by machine learning models. The process of generating a vector for a data object is called vectorization. Weaviate generates vector embeddings using integrations with model providers (OpenAI, Cohere, Google PaLM etc.), and conveniently stores both objects and vector embeddings in the same database. For example, vectorizing the two words above might result in the following word embeddings:
cat = [1.5, -0.4, 7.2, 19.6, 3.1, ..., 20.2]
kitty = [1.5, -0.4, 7.2, 19.5, 3.2, ..., 20.8]
These two vectors have a very high similarity. In contrast, vectors for “banjo” or “comedy” would not be very similar to either of these vectors. To this extent, vectors capture the semantic similarity of words.
How to create vector embeddings?
-
Word-level dense vector models (word2vec, GloVe, etc.)
-
Transformer models (BERT, ELMo, and others)
Vector embedding visualization
Below we can see what vector embeddings of data objects in a vector space could look like. The image shows each object embedded as a 3-dimensional vectors for ease of understanding, realistically a vector can be anywhere from ~100 to 4000 dimensions.
In the following image, you can see the vectors for the words “Wolf” and “Dog” are close to each other because dogs are direct descendants of wolves. Close to the dog, you can see the word “Cat,” which is similar to the word “Dog” because both are animals that are also common pets. But further away, on the right-hand side, you can see words that represent fruit, such as “Apple” or “Banana”, which are close to each other but further away from the animal terms.
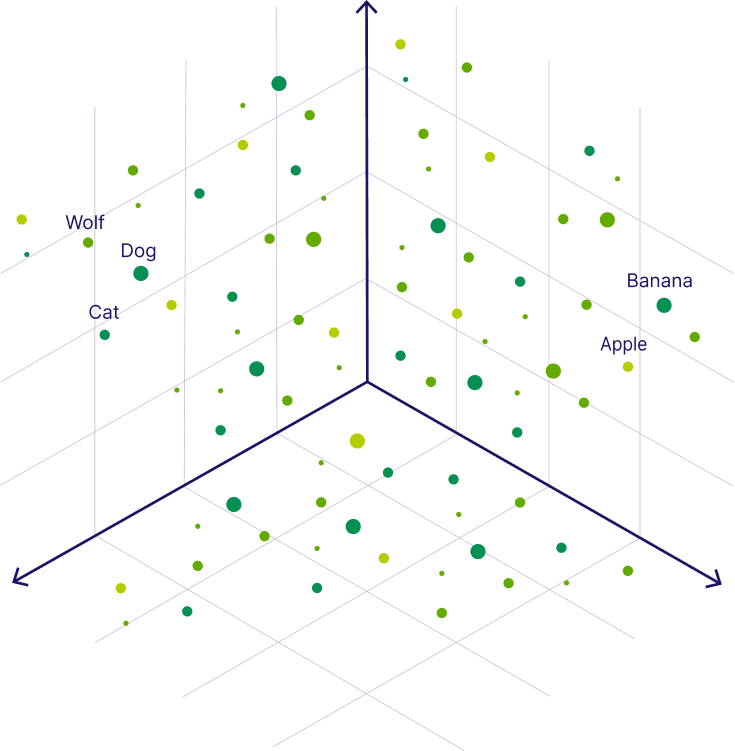
Semantic Search
Vector Comparison
Private Embedding
Distance Preserving Encryption
DPE" stands for "Distance Preserving Encryption," which refers to a type of encryption scheme designed to maintain the relative distances between data points even after encryption, meaning the distance calculated between two encrypted pieces of data should be the same as the distance between their original, unencrypted counterparts.
YAK implements a form of property preserving encryption to encrypt vector embeddings in such a way that they can still be used for the common use cases of nearest neighbor search and clustering based on their similarity to other vectors. The property that is preserved by the encryption is the distance between vectors. Like other forms of property-preserving encryption, a tradeoff is made between the most secure protection of the data and the usability of the data in its encrypted form.
Definition
Let D be a data set, d be a distance measure and Enc an encryption algorithm for data items in D. Then, Enc is d-distance preserving if ∀x,y ∈ D : d(Enc(x), Enc(y)) = d(x,y). Distance-preserving encryption enables distance-based data mining on encrypted data sets.
DPE in Theory
Encrypting Vector Elements
The core idea of the technique is to scale the elements of the vector by a secret factor, then to perturb the elements of the scaled vector by adding a random vector to it. This perturbation is pseudorandom, based on a secret key. The idea is that the amount of perturbation of each individual element is uniformly distributed within a range defined by a value that we refer to as the approximation factor. Conceptually, for a vector with n elements, the encryption can be viewed as choosing a new point that lies within an n-dimensional sphere centered on the point represented by the vector whose radius is determined by the scaling factor and approximation factor. The choice of the point is pseudorandom rather than fully random so that the encrypted vector can be decrypted given the same key.
The larger the approximation factor, the more difficult it is to guess what the original point was, but the less accurate the results of nearest neighbor searches are. The choice of approximation factor must balance the need for security with the need for accuracy.
Shuffling Vector Elements
After the vector has been encrypted, we reorder the elements of the vector by applying a deterministic shuffling algorithm that is based on a secret value. Like the choice of scaling factor and secret used to encrypt the vector elemetns, the same shuffling secret is used for all the vectors in the same data segment, but a different secret is used for each segment.
AutoPE
AutoPE(APE, Automatical Prompt Engineering) refers to the approach in which prompts are automatically generated by LLMs rather than by humans. The method, introduced in the “Large Language Models Are Human-Level Prompt Engineers” paper, involves using the LLM in three ways: to generate proposed prompts, to score them, and to propose similar prompts to the ones scored highly (see diagram below).
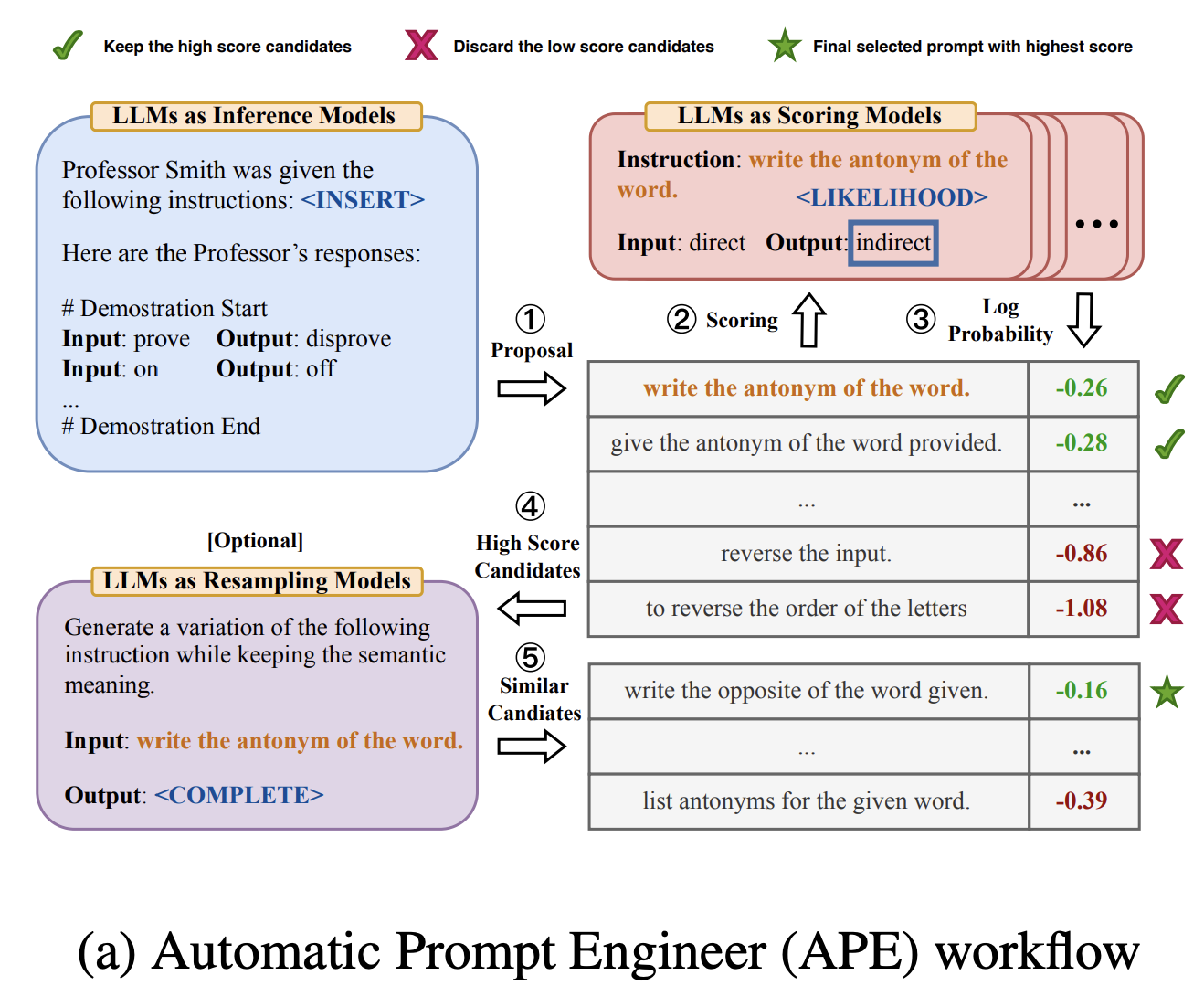
Prompt Enginnering
Prompt engineering is a relatively new discipline for developing and optimizing prompts to efficiently use language models (LMs) for a wide variety of applications and research topics. Prompt engineering skills help to better understand the capabilities and limitations of large language models (LLMs).
Researchers use prompt engineering to improve the capacity of LLMs on a wide range of common and complex tasks such as question answering and arithmetic reasoning. Developers use prompt engineering to design robust and effective prompting techniques that interface with LLMs and other tools.
Prompt engineering is not just about designing and developing prompts. It encompasses a wide range of skills and techniques that are useful for interacting and developing with LLMs. It's an important skill to interface, build with, and understand capabilities of LLMs. You can use prompt engineering to improve safety of LLMs and build new capabilities like augmenting LLMs with domain knowledge and external tools.
Motivated by the high interest in developing with LLMs, we have created this new prompt engineering guide that contains all the latest papers, advanced prompting techniques, learning guides, model-specific prompting guides, lectures, references, new LLM capabilities, and tools related to prompt engineering.
Techniques
- Techniques
- Zero-shot Prompting
- Few-shot Prompting
- Chain-of-Thought Prompting
- Meta Prompting
- Self-Consistency
- Generate Knowledge Prompting
- Prompt Chaining
- Tree of Thoughts
- Retrieval Augmented Generation
- Automatic Reasoning and Tool-use
- Automatic Prompt Engineer
- Active-Prompt
- Directional Stimulus Prompting
- Program-Aided Language Models
- ReAct
- Reflexion
- Multimodal CoT
- Graph Prompting
AutoPE with RAG
RAG is a technique that has been used for some time to augment LLMs. It was presented by Facebook as a way to improve BART in 2020 and released as a component in the Huggingface library.
The idea is simple: combine a retrieval component with a generative one such that both sources complement each other (see diagram below from the paper.
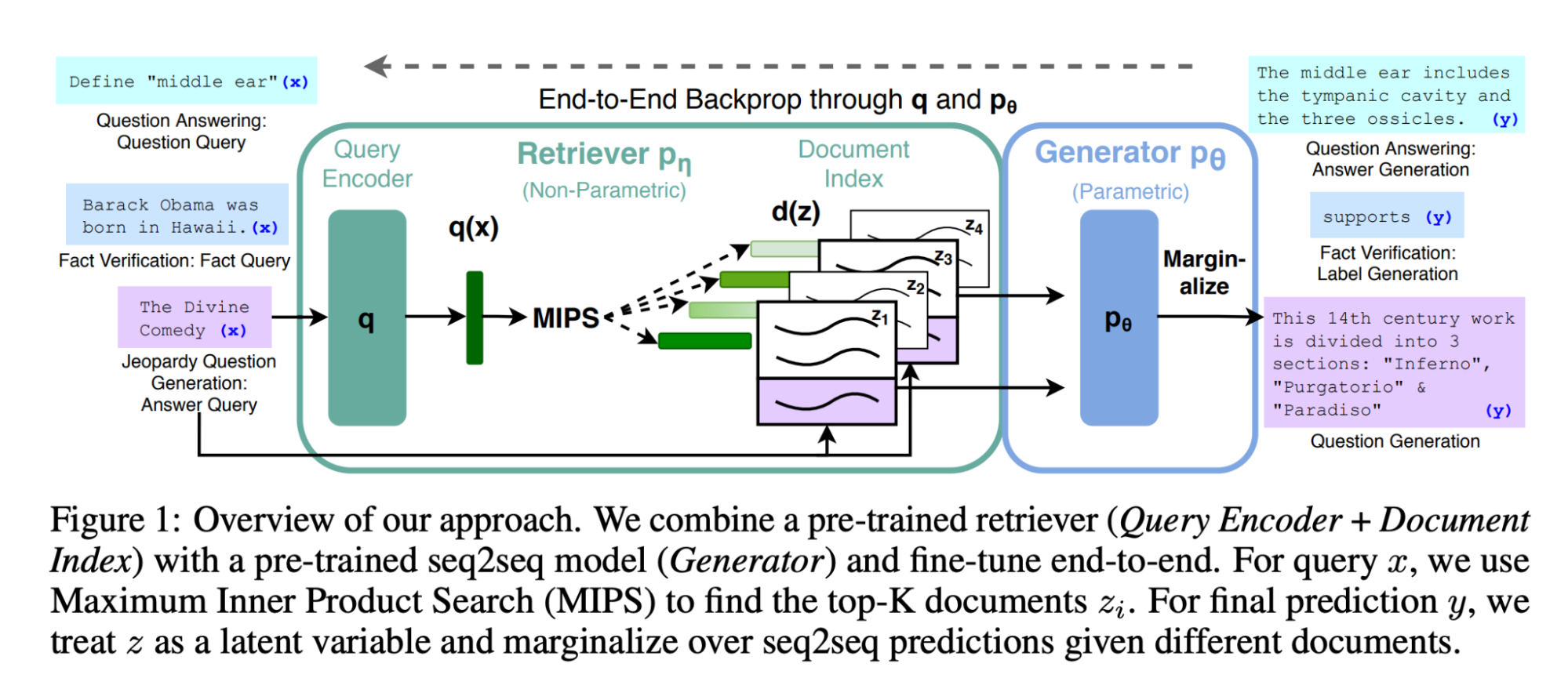
Developer Tutorial
API
Run
cargo doc --open --lib
and you can search rig to find the API.